用 OpenClaw 搭建个人运动助手
别再让它瞎聊天了,把它变成真正懂你、能干活的运动助手。

前言
最近掉进了 OpenClaw("小龙虾")的坑里,越玩越觉得这玩意儿底子不错,特别适合改造成一个能7x24小时跑着的个人助手。
我平时的爱好就是跑步和徒步,所以脑子一热,冒出一个很具体的想法:能不能把它从一个"聊天机器人",改造成一个真正懂我的运动搭档?不是那种你问一句它答一句的被动工具,而是能主动扒我的跑步数据、帮我生成训练计划并塞进 Garmin,甚至在我跑完后,像私教一样甩给我一份深度分析报告。
折腾了一圈下来,我发现这事儿不仅能成,而且一旦跑通了,体验极其丝滑。而真正的关键,不在于让 AI 什么都自己瞎琢磨,而在于把那些天天干的破事儿给它固化下来。这样既省 Token(心疼钱),又好用。
硬件和工具:够用就好
我的配置很简单,没啥高大上的:
- 设备:树莓派 5(放角落吃灰的最佳选择)
- 运动手表:佳明 Garmin (续航长、开放接口)
- 聊天入口:Telegram Bot(手机上点一下就完事儿)
树莓派 5 这种小东西简直是为此而生:24 小时在线、功耗低得可怜、没噪音,放那儿你都感觉不到它的存在。而 Telegram Bot 的好处是,我可以自定义菜单按钮,懒人福音。日常用的时候,打开 Telegram,戳一下菜单,今天的健康数据、昨晚睡得怎样、最近一次跑得咋样,全出来了。
说真的,这一点对"可用性"至关重要。咱折腾这玩意儿是拿来用的,不是截个图发朋友圈炫耀一下就完事儿的。
第一个坑:Token 烧得我心在滴血
OpenClaw 默认会在 workspace 目录下给你塞一大堆上下文文件,什么人格设定啊、用户档案啊、工作规则啊、会话记忆啊。听着挺高级,问题在于,每次跑起来它都把这些玩意儿全带进上下文。后果就是,Token 消耗速度堪比烧钱。
我当时天真地接了 DeepSeek 的 API,心想这总便宜了吧?结果跑了两天,一看账单:好家伙,几天就烧了不少钱。问题不在单次调用,而在于它一碰到"模糊任务",就跟无头苍蝇似的:疯狂试探、写一堆临时破代码、反复确认上下文。一圈圈下来,Token 没少花,真正干的事儿没多少。
后来我换了 Claude 来帮我完善运动助手的需求,明显感觉它在这类任务上更靠谱,思路清晰,不绕弯子,从需求到代码一步到位。当然,日常跑"小龙虾"的 API 调用我还是用 DeepSeek,毕竟穷,这玩意儿价格真香,而且中文理解力也好。
这事儿让我彻底想明白一个理儿:那些天天干的、确定性的活儿,千万别让 AI 现场瞎想,你得先把这些活儿工程化。
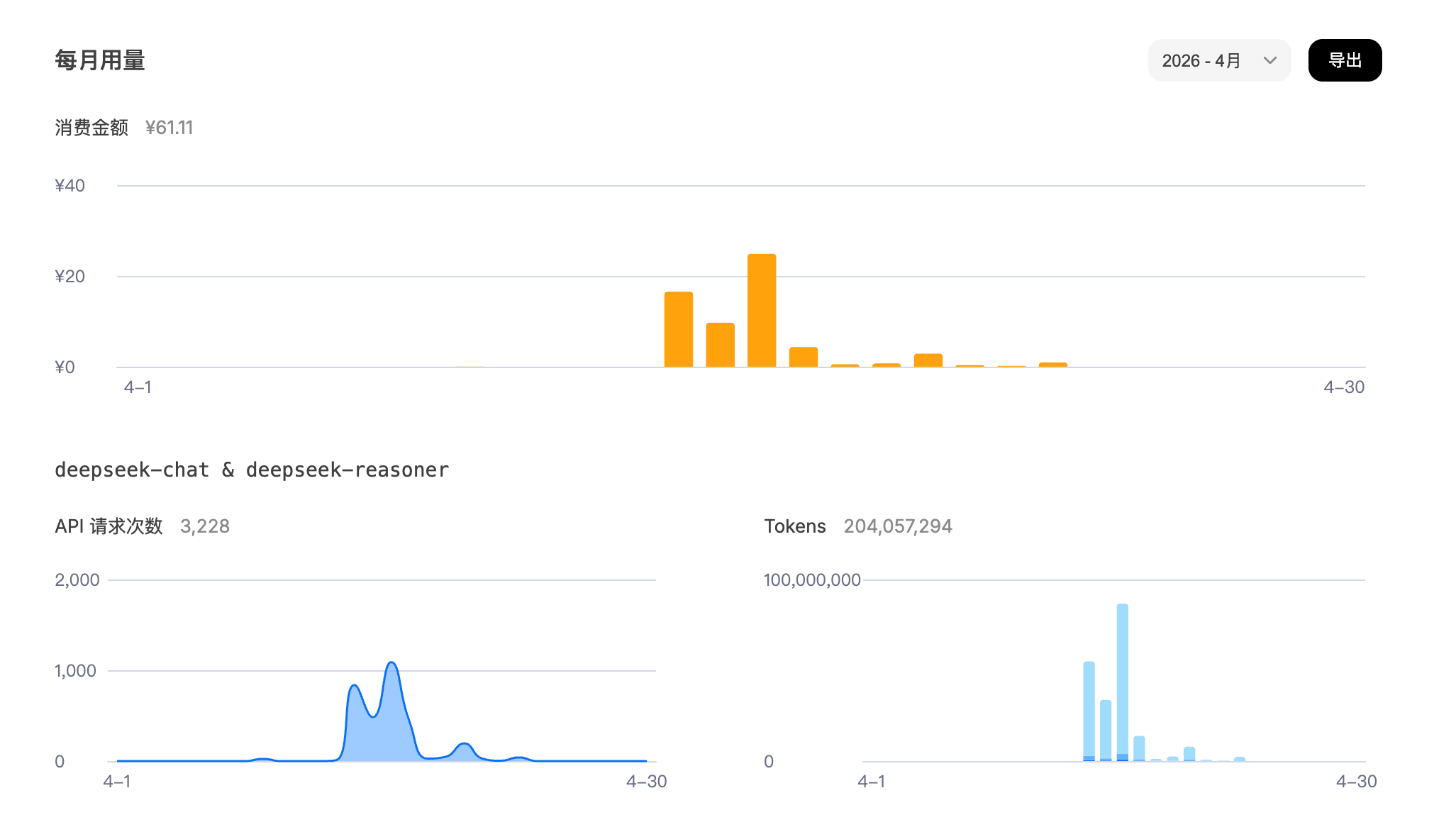
上图很直观,前几天需求模糊的时候,使用量直接起飞(一天 Token 干了 8 千万)。等我把那些破事儿都固化成工程化任务之后,消耗直接降到之前的 1% 都不到(不到2毛钱)。
核心思路:三步让"小龙虾"真正干活
整个方案总结下来就三步,简单粗暴但极其有效:
- 把常用命令写成脚本
- 把脚本包装成 OpenClaw Skill
- 把"查数据"和"分析"拆开,各干各的
别看就三步,这是"玩具"和"工具"的区别。
第一步:把高频操作直接写成脚本
别犯懒。与其每次让 AI 临时抱佛脚想"怎么从 Garmin 拿数据"、"怎么生成训练计划",不如你自己把这些破事儿封装成脚本。
所有脚本都塞进 Skill 目录里,统一管理。比如,我把最常用的数据查询命令都收进 garmin_commands.py:
# 今日健康数据
python3 skills/garmin-workout/scripts/garmin_commands.py health_data
# 昨夜睡眠分析
python3 skills/garmin-workout/scripts/garmin_commands.py sleep_analysis
# 最近一次跑步
python3 skills/garmin-workout/scripts/garmin_commands.py last_run
训练生成和推送,则走另一个入口 skill.py:
# 生成并推送轻松跑到 Garmin Connect
python3 ~/.openclaw/workspace/skills/garmin-workout/scripts/skill.py \
--command generate_and_push --args '{"command": "/easy_run 8公里 明天"}'
这么做的意义简单直接:AI 别再跟我这装聪明了,你需要做的只是"调用工具"
我设置了 6 种自定义训练类型,每种都预设了对应的结构和配速,省得它瞎编:
| 命令 | 类型 | 结构 |
|---|---|---|
/easy_run | 轻松跑 | 热身 → 主跑 @6:30–7:00/km → 放松 |
/tempo_run | 节奏跑 | 热身 → 主跑 @5:20–5:40/km → 放松 |
/long_run | 长距离跑 | 热身 → 主跑 @5:50–6:10/km → 放松 |
/interval_run | 间歇跑 | 热身 → repeat 结构 → 放松 |
/recovery_run | 恢复跑 | 热身 → 主跑 @7:15–7:45/km → 放松 |
/fartlek_run | 法特莱克 | 热身 → repeat 结构 → 放松 |
搞定这一步之后,日常命令几秒钟就响应,而且几乎不花一分钱推理成本。
第二步:把脚本包装成 OpenClaw Skill
光有脚本还不够,想让"小龙虾"自己知道啥时候该用,得把它包装成 Skill。
Skill 的核心是一个 SKILL.md 文件,放在 skills/garmin-workout/ 里。它本质上是在告诉 AI:
- 这玩意儿是干啥的
- 遇到啥需求的时候应该用它
- 命令长啥样
- 参数怎么传
比如说:
---
name: garmin-workout
description: Garmin Connect integration for running training. Use when user asks about
workouts, training plans, pushing sessions to Garmin Connect, health data
(sleep, VO2 Max, heart rate, body battery, stress). Covers all 6 workout types.
---
这一步非常关键,因为它解决了一个现实问题:AI 每次重启都是个健忘症患者,你不能指望它"记住"啥,你得给它一个结构化的入口让它自己找。
脚本放那儿,只是个工具; 你把 Skill 写清楚了,AI 才知道这玩意儿是干嘛的、啥时候该用。
SKILL.md 的最后一部分,我把所有 Telegram 命令和对应的执行脚本做了完整映射,比如:
| Telegram 命令 | 执行脚本 |
|---|---|
/last_run | python3 .../garmin_commands.py last_run |
/sleep_analysis | python3 .../garmin_commands.py sleep_analysis |
/easy_run 8km 明天 | skill.py --command generate_and_push ... |
规则也写得贼直接:
收到这些命令后,立即运行对应脚本并原样返回输出;不要再追问用户想要什么数据,也不要临时生成探索性代码。
这么搞完之后,系统稳如老狗:不绕路、不试探、不反复确认,直接干。
顺带一提,AGENTS.md 是另一回事——它是 workspace 的核心行为规范,管的是记忆写入规则、心跳检查逻辑、群聊行为准则这些。每次 session 启动时,它还会静默跑一次 update_menu,把 Telegram Bot 的 23 个自定义命令恢复到位,省得被系统默认菜单覆盖掉。
第三步:把 AI 的好钢用在刀刃上(分析)
把高频任务都脚本化,不是说要放弃 AI 的价值。恰恰相反,需要 AI 出场的地方是"分析",而不是"查数据"。
举个例子,我跑完步之后,先发个 /last_run,拿到结构化的数据摘要:
🏃 2026-04-21 跑步数据
📋 Xuhui - 节奏跑 5.0km_2026-04-21
📏 距离: 5.09 km
⏱️ 用时: 33分钟
⚡ 均速: 6:30/km
🚀 最快1km: 5:38
🚀 最快5km: 32:19
💓 均心率: 139 bpm
🔴 最大心率: 162 bpm
...(此处省略一部分)
这一阶段完全是脚本执行,几乎不花钱。 然后我才会追问:"这次跑得咋样?下次咋调整?"这时候才让 AI 进入分析模式。
它就可以基于心率、配速、步频这些指标,给我像真人教练一样的建议,比如:
包大人,相比 4 月 17 号的节奏跑(7:03/km,心率 132),你这次配速提了 33 秒/公里;
心率从 132 到 139 bpm,强度上去了,很可以;
训练效果也从 2.8 干到 3.0,进步肉眼可见。
我后来觉得,这种"两步走"的设计简直是精髓:
- 查询走脚本,又快又稳又省钱
- 分析交给 AI,慢点没关系,但要有干货
就因为做了这个拆分,这套系统才真正变得既好使又有 AI 的价值。
实际体验:它终于像个真正能干活儿的助手了
现在我的 Telegram 菜单里,大概有这么些东西。
训练相关
/training_plan—— 瞅一眼下周练啥/easy_run 5km 今天—— 生成轻松跑,推 Garmin/tempo_run 8km 明天—— 生成节奏跑/long_run 10km 周末—— 生成长距离训练/interval_run 今天—— 生成间歇跑/garmin_workouts—— 看这周的训练排期/weekly_review—— 本周训练总结/race_readiness—— 比赛准备度评估/pace_progress—— 配速进步趋势(可指定周数)
健康数据相关
/health_data—— 今日身体状况咋样/sleep_analysis—— 昨晚睡得死不死/last_run—— 最近一次跑得咋样/running_stats—— 过去 7 天数据统计/body_battery—— 现在身体还有多少电/vo2max—— 最大摄氧量趋势/heart_rate—— 今日心率数据/stress_level—— 压力水平
比如我发一条:
/easy_run 8公里 明天
几秒钟之后,打开 Garmin Connect,明天的日历上就会多出一条训练:热身、主跑、放松,配速目标都给你设好了。
这感觉真的不一样。它不再是个"你问我答"的聊天工具,而是一个真的能帮你执行动作的个人运动助手。
当前目录结构(不乱,很舒服)
整个项目目前长这样:
~/.openclaw/workspace/
├── AGENTS.md # Workspace 核心行为规范(记忆、心跳、群聊规则)
├── IDENTITY.md # AI 身份定义(名字、角色、头像)
├── SOUL.md # AI 人格与行为准则
├── USER.md # 用户信息
├── TOOLS.md # 本地工具配置(SSH、设备别名等)
├── HEARTBEAT.md # 定时巡检任务清单
├── memory/ # 会话记忆(按日期归档)
├── profiles/ # 用户画像
├── state/ # 运行时状态存储
└── skills/
└── garmin-workout/
├── SKILL.md # 技能描述 + Telegram 命令路由(AI 的入口)
├── runner_profile.json # 跑者配置文件
├── training_plan_state.json # 训练计划持久化状态
├── scripts/
│ ├── garmin_commands.py # 健康数据统一入口
│ ├── skill.py # 训练生成 + 推送
│ ├── garmin_auth.py # 认证管理
│ ├── generate_workout.py # 生成训练 JSON
│ └── garmin_push.py # 底层推送(含 repeat 展开)
└── workouts_template/
├── easy_run_5km.json
├── tempo_run_5km.json
├── long_run_10km.json
├── recovery_run_3km.json
├── interval_run_simple.json
└── fartlek_run_simple.json
从工程角度看,这种结构的好处是:职责清晰、好维护、以后想加啥新功能也方便。
特别值得一说的是 training_plan_state.json——这是我后来加的一个小细节,用来持久化每周的训练安排。以前调整了训练计划,重启一次 session 就全没了。现在每次修改计划后,会立刻把数据写进这个文件,下次打开 /training_plan,内容还在那儿。这种"写下来,别靠记"的设计理念,跟整个系统的思路完全一致。
备份这事儿,想在前头
OpenClaw 的配置、记忆和技能全在 ~/.openclaw 里。所以最直接的办法,就是定期把这个目录打包。
# 备份整个 openclaw 配置
tar -czf openclaw_backup_$(date +%Y%m%d).tar.gz ~/.openclaw
# 或者只备份 workspace(技能、脚本、记忆)
tar -czf workspace_backup_$(date +%Y%m%d).tar.gz ~/.openclaw/workspace
再加个 cron 定时任务,每天自动同步到网盘或 NAS。这样就算哪天树莓派的 SD 卡挂了,训练记忆、Skill 配置、训练计划状态、Telegram 菜单这些关键东西都能很快救回来。
对于这种长期跑着的个人助手,备份不是"以后再说",而是从第一天就得想好的事儿。
总结
折腾这一圈下来,我最大的感受是: 想把这玩意儿做成一个真正好用的个人运动助手,关键不在于让 AI 更"聪明",而在于让系统的分工更清楚。
核心思路就这么简单:
- 高频操作直接固化成脚本:Garmin 查数据、生成训练,这种确定性的活儿,别让 AI 即兴发挥
- 用 Skill 固化入口:让 AI 每次启动都知道工具在哪儿、啥时候该用,Telegram 命令路由也一并管起来
- 把查询和分析拆开:天天查数据走脚本(省钱、快),深度建议才交给 AI(保质、有料)
- 状态持久化:训练计划、跑者画像这些东西,写进文件,别靠 AI 的"记忆"
当树莓派 7x24 小时在线,Telegram 成了你的交互入口,Garmin 负责落地执行,这整套系统就不再只是一个"能聊天的 AI",而更像一个真正融入你生活的运动搭档。
相关项目
Github 地址: sayidhe/openclaw-garmin-workout